K Nearest Neighbor (KNN) adalah salah satu algoritma paling populer dalam data mining dan machine learning yang digunakan untuk klasifikasi maupun prediksi. Algoritma ini bekerja dengan konsep sederhana, yaitu menentukan kelas suatu data berdasarkan kedekatannya dengan data lain yang sudah diketahui sebelumnya. Karena pendekatannya yang intuitif, KNN sering menjadi pilihan pertama bagi pemula yang ingin memahami dasar-dasar machine learning.
Kalau kamu penasaran bagaimana sebuah sistem bisa menentukan kategori hanya berdasarkan “kemiripan data”, maka algoritma KNN adalah jawabannya. Dengan menghitung jarak antara data baru dan data training, KNN mampu mengelompokkan data secara efektif tanpa perlu proses training yang kompleks. Pada artikel ini, kamu akan mempelajari secara lengkap mulai dari pengertian KNN, cara kerja, rumus perhitungan jarak, hingga contoh penerapannya di dunia nyata.
Apa Itu K Nearest Neighbor (KNN)?
K Nearest Neighbor (KNN) merupakan algoritma klasifikasi yang bekerja dengan mengambil sejumlah nilai K data terdekat (tetangganya) sebagai acuan untuk menentukan kelas dari data baru. KNN mengklasifikasikan data berdasarkan similarity atau kemiripan atau kedekatannya terhadap data lainnya.
Algoritma KNN ini bersifat lazy learning yang berarti tidak menggunakan titi data training untuk membuat model. Singkatnya pada algoritma KNN sangat minim ada fase training.
Tujuan dari algoritma ini adalah untuk mengklasifikasi objek baru berdasarkan atribut dan sample-sample dari data training.
Baca Juga: Belajar Data Mining: Pengertian, Metode Dan Cara Kerja
Cara Kerja K Nearest Neighbor (KNN)
Adapun alur cara kerja KNN sebagai berikut

- Tahap 1 : Tentukan jumlah tetangga terdekat (K) yang akan dipertimbangkan sebagai dasar klasifikasi.
- Tahap 2 : Hitung jarak antara data baru yang ditanyakan dengan seluruh sampel data pelatihan (data training).
- Tahap 3 : Urutkan seluruh jarak berdasarkan jarak minimum dan tetapkan tetangga sesuai dengan nilai K.
- Tahap 4 : Sesuaikan klasifikasi dari kategori Y dengan tetangga yang telah ditetapkan.
- Tahap 5 : Gunakan kelas dengan jumlah terbanyak sebagai dasar menentukan kelas dari data baru yang ditanyakan.
Perhitungan jarak ke tetangga terdekat (tahap 2) dapat dilakukan dengan menggunakan metode, adapun metode yang sering digunakan sebagai berikut.
Euclidean Distance
Rumus Euclidean Distance digunakan untuk menghitung jarak antara dua titik dan dalam ruang berdimensi n. Metode ini menghitung jarak garis lurus (straight line distance) dengan menjumlahkan kuadrat selisih setiap atribut, kemudian diakarkan. Semakin kecil nilai jarak yang dihasilkan, semakin mirip kedua data tersebut.
Baca Juga: Euclidean Distance: Cara Kerja, Rumus dan Contoh Perhitungan
Rumus Manhattan Distance
Manhattan Distance menghitung jarak antara dua titik dengan menjumlahkan nilai mutlak selisih setiap atribut. Metode ini sering digunakan pada data berdimensi tinggi dan dikenal juga sebagai city block distance, karena perhitungannya menyerupai jarak tempuh di jalanan kota berbentuk grid.
Baca Juga: Manhattan Distance: Konsep, Rumus, dan Contoh
Rumus Hamming Distance
Hamming Distance digunakan untuk menghitung jarak antara dua vektor biner. Jarak dihitung berdasarkan jumlah posisi atribut yang berbeda antara dua data. Jika nilai atribut sama maka jaraknya 0, sedangkan jika berbeda maka jaraknya bernilai 1. Metode ini umum digunakan pada data kategorikal atau biner.
Rumus Minkowski Distance
Minkowski Distance merupakan bentuk umum dari perhitungan jarak dalam metode KNN. Rumus ini menggeneralisasi Euclidean dan Manhattan Distance. Ketika nilai , rumus ini akan menjadi Manhattan Distance, dan ketika , rumus ini menjadi Euclidean Distance.
Cara Menentukan Nilai K Pada K Nearest Neighbor
Nilai K pada KNN adalah jumlah tetangga terdekat yang digunakan oleh algoritma dalam proses klasifikasi maupun regresi. Nilai K ditetapkan dengan nilai ganjil untuk menghindari adanya kesamaan jarak yang dapat muncul dapa proses KNN dijalankan.
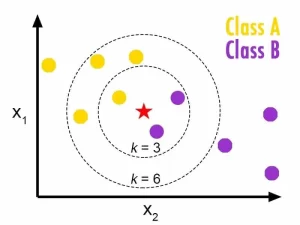
Adapun beberapa pertimbangan yang dapat digunakan untuk menentukan nilai K.
- Jika bekerja pada dua kelas (class) atau kategori, gunakan nilai K ganjil untuk menghindari jumlah kelas yang sama pada saat perhitungan kelas K.
- Nilai K yang sangat kecil (K=2 atau K=3) mengakibatkan hasil kurang akurat, terutama jika ada banyak outlier dalam data kita. Selain itu, penggunakan K kecil dapat mengarahkan kita pada model yang overift.
Baca Juga: Naive Bayes Adalah: Pengertian, Tujuan dan Penerapannya
Contoh Penerapan K-Nearest Neighbor
- Pengenalan Pola : KNN dapat digunakan untuk mengidentifikasi pola. contoh mengidentifikasi pola dalam pembelian pelanggan.
- Peramalan pasar saham : KNN dapat memprediksi harga saham berdasarkan kinerja perusahaan dan data-data ekonomi.
- Preprocessing Data : KNN digunakan untuk proses yang disebut missing data imputation yang memperkirakan nilai-nilai yang hilang.
- Sistem rekomendasi : KNN dapat membantu menemukan pengguna (user) dengan karakteristik serupa dan dapat digunakan dalam sistem rekomendasi.
- Visi komputer : KNN digunakan untuk klasifikasi gambar, karena mampu mengelompokan titik data yang serupa.
Kelebihan K Nearest Neighbor (KNN)
- Sangat mudah diterapkan.
- Sangat sederhana dan mudah dipahami.
- Parameter yang diperlukan sedikit, hanya jumlah tetangga yang dipertimbangkan (K) dan metode perhitungan jaraknya.
- Hasil pemodelan tidak linear, sehingga cocok untuk klasifikasi daya yang batasannya tidak linear.
- Tidak memerlukan proses training dan proses pembangunan model, karena data baru lansung dikelaskan.
- Dapat digunakan dalam proses jumlah kelas (class) yang berbeda-beda.
- Dapat digunakan dalam proses klasifikasi maupun regresi.
Kekurangan K Nearest Neighbor (KNN)
- Perlu menentukan nilai K yang tepat.
- Sangat sensitif pada data yang memiliki banyak noise (noisy data), banyak data yang hilang (missing data), dang pecilan (outliers).
- Tidak cukup bagus diterapkan pada high dimensional data.
- Membutuhkan waktu yang lama dalam pemprosesan jika data set (data training) sangat besar.
- Biaya pembuatan dan perawatan yang mahal.
Baca Juga: Belajar Decision Tree: Pengertian, Konsep, Penerapan dan Cara Kerjanya
Kesimpulan
Pada pembelajaran kita di atas dapat disimpulkan bahwa Algoritma K Nearest Neighbor (KNN) adalah algoritma machine learning yang berfokus pada konsep sederhana tetapi efektif, yaitu dengan memanfaatkan tetangga terdekat untuk melakukan prediksi atau klasifikasi. KNN memiliki sejumlah kelebihan, seperti kemudahan implementasi, adaptabilitas tinggi dan ketidakbergantungan pada asumsi kompleks tentang data. Namun, perlu diperhatikan bahwa KNN juga memiliki keterbatasan, seperti sensitivitas terhadap outlier dan kebutuhan akan jumlah data latih yang mencukupi.
Dalam penggunaan praktisnya, KNN telah menemukan berbagai aplikasi di dunia nyata, termasuk dalam pengenalan pola wajah dan sistem rekomendasi. Meskipun sederhana, algoritma ini masih sangat relevan dalam konteks kecerdasan buatan, terutama dengan kemajuan teknologi yang terus berlanjut. KNN tetap menjadi alat yang berguna dan bermanfaat dalam analisis data dan pengambilan keputusan.
Artikel ini merupakan bagian dari seri Kecerdasan Buatan KantinIT.com. Jika artikel ini bermanfaat, jangan lupa bagikan ke media sosial atau ke teman kamu.